 Science
in Christian Perspective
Science
in Christian PerspectiveScience
in Christian Perspective
Similarities and Differences in Mitochondrial
Genomes:
Theistic Interpretations
Gordon Mills*
Department of Human Biological Chemistry and Genetics
University of Texas Medical Branch
Galveston, TX 77555
From: Perspectives on Science and Christian Faith 50 (December 1998: 286-291.
Often-cited molecular biological arguments for ancestral descent of all living organisms from a single archetypal organism have been based on similarities: similarities in the genetic code, in cellular metabolism, in genome arrangements, and in protein and DNA sequences. In most discussions, dissimilarities or differences receive little attention. Yet, surely differences are as important as similarities in regard to any broad-based theory of organismal relationships.
In this paper, I will examine the similarities and differences of organisms from their mitochondrial DNA (mDNA). I will attempt to evaluate the data from the standpoint of evolution as occurring as a consequence of purely chance events, or as occurring in some manner as a response to a provision of guidance and information by an intelligent cause. Is M. A. Corey correct when he notes "that the process of biological evolution is not only fully consistent with the existence of a Grand Designer, it is also positively unintelligible in the absence of one"?1 Only in the past twenty to thirty years, have scientists recognized that some cellular organelles, such as chloroplasts and mitochondria in plants and mitochondria in animals, have genetic DNA that is synthesized and used independently of DNA in the cell nucleus. These are independent in the sense that DNA is synthesized in these organelles as the need arises, and that a unique genetic code is often used.
A considerable amount of information is available regarding mDNAs of the simplest eukaryotic organisms (ciliate protozoa, kinetoplastic protozoa, fungi, etc.).2 These mDNAs are quite variable in structure and in most cases are much more complex (i.e., have larger genomes) than mDNAs of higher animals. The mDNAs of higher plants are also larger and more variable than mDNAs of higher animals.
Table 1. Sizes of Some Sequenced Genomes
Nudeotide pairs
Bacteria: H.
influenza 1,830,121 Mycoplasma 580,070Plant chloroplast: Liverwort
121,024Nfitochondriaa
Mammaha (human, mouse, cow, and fin whale) 16,295-16,569 Arnphibia (South African clawed toad) 17,553
Echinodermata. (sea urchin, starfish) 15,650-16,200
Arthropoda (fruit fly, honey bee) 16,019-16,343
Nematoda (soil, gut, and root nematodes) 13,794-20,500
Cnidaria (sea anemone) 17,443
aFor references to these studies, see D. R. Wolstenholme, "Animal Nfitochondrial DNA: Structure and Function,"
International Review of Cytology 141 (1992): Table L
Although my intention is to restrict the discussion to a
consideration of some similar mDNAs found in multicellular animals (metazoa),
some comparisons of potential genome size in various cells and organelles is
worth noting (see Table 1). By comparison, the nuclear genome of C. elegans
has ca. 100,000,000 nucleotide pairs. In nearly all metazoan mDNA, we are
dealing with a circular DNA molecule and a comparatively small number of
nucleotide base pairs (14,000ñ42,000). Also, a major portion of that DNA is
involved in reading frames for either transfer RNA (tRNA), ribosomal RNA (rRNA),
or protein sequences. In most cases, the remaining DNA is involved in control of
either DNA replication (i.e., making new copies of DNA) or transcription of DNA
into RNA sequences. The mDNA of these animals, ranging from sea anemone to
humans, is also unique in having very short segments of nucleotide base pairs
between genes, or none at all. In a few instances, mDNA genes even overlap by a
few base pairs.
control of
either DNA replication (i.e., making new copies of DNA) or transcription of DNA
into RNA sequences. The mDNA of these animals, ranging from sea anemone to
humans, is also unique in having very short segments of nucleotide base pairs
between genes, or none at all. In a few instances, mDNA genes even overlap by a
few base pairs.
Significance of Mitochondria
To discuss mDNA adequately, a brief consideration of mitochondrial function is necessary. Mitochondria are potato-shaped organelles found within cells of eukaryotic organisms (i.e., those with a cell nucleus), which have a very specialized function. Although mitochondria contain many different enzymes, they are concerned primarily with production of the energy-rich molecule, adenosine triphosphate (ATP), to supply the energy needs of the cell. This function is carried out by a process known as respiratory chain phosphorylation, by which hydrogens from a substrate molecule are linked in coupled sequential reactions and ultimately combine with oxygen to produce water. The energy produced in this oxidative process is trapped by the mitochondria as ATP for use by the cell.
Most of the genetic information for the production of mitochondrial enzymes comes from the DNA of the cell nucleus. Therefore, most mitochondrial enzymes are synthesized in the cell cytoplasm and transported into the mitochondria where they function. Cytochrome c is an example of this type. In contrast, five other enzyme components of the mitochondrial respiratory chain (NADH dehydrogenase, cytochrome b, cytochrome oxidase, and two ATPases) are coded by mDNA and synthesized within the mitochondria. The mDNA also codes for about 22 different tRNA molecules and two different rRNA molecules. In contrast to nuclear DNA, mDNA is nearly always circular, with the two helical chains referred to as H (heavy) and L (light) chains, respectively.
Gene Size and Genome Arrangement
Table 2 gives an example of gene size and arrangement for
protein reading frames and for rRNA genes found in  mDNA of higher animals. Note
that of thirteen protein coding genes, seven are for a single complex enzyme (NADH
dehydrogenase), and three make up the cytochrome oxidase component. In
representatives of five different classes (Mammalia, Mus musculus, a
mouse; Echinodermata, Paracentrotus lividus, a sea urchin; Arthropoda, Drosophila
yakuba, a fruit fly; Nematoda, Caenorhabditis elegans, a soil
nematode; and Cnidaria, Metridium senile, a sea anemone), total reading
frames for the thirteen protein genes vary from 3523 to 3963 codons (10,569 to
11,889 nucleotide base pairs), while the reading frames for the individual genes
vary in length (mean values) from 61 codons (183 nucleotide base pairs) for the
ATPase8 gene to 609 codons (1827 nucleotide base pairs) for the ND5 gene.3
With these five different class representatives, there is a maximum variability
in length for individual genes of 3ñ39% (mean 18%) for the thirteen protein
reading frames. Clearly, some genes have more variability in length than others.
This comparison indicates considerable similarity in gene size among organisms
as widely separated as a mouse, a sea urchin, a fruit fly, a soil nematode, and
a sea anemone. However, it also points out some major differences that must be
explained.
mDNA of higher animals. Note
that of thirteen protein coding genes, seven are for a single complex enzyme (NADH
dehydrogenase), and three make up the cytochrome oxidase component. In
representatives of five different classes (Mammalia, Mus musculus, a
mouse; Echinodermata, Paracentrotus lividus, a sea urchin; Arthropoda, Drosophila
yakuba, a fruit fly; Nematoda, Caenorhabditis elegans, a soil
nematode; and Cnidaria, Metridium senile, a sea anemone), total reading
frames for the thirteen protein genes vary from 3523 to 3963 codons (10,569 to
11,889 nucleotide base pairs), while the reading frames for the individual genes
vary in length (mean values) from 61 codons (183 nucleotide base pairs) for the
ATPase8 gene to 609 codons (1827 nucleotide base pairs) for the ND5 gene.3
With these five different class representatives, there is a maximum variability
in length for individual genes of 3ñ39% (mean 18%) for the thirteen protein
reading frames. Clearly, some genes have more variability in length than others.
This comparison indicates considerable similarity in gene size among organisms
as widely separated as a mouse, a sea urchin, a fruit fly, a soil nematode, and
a sea anemone. However, it also points out some major differences that must be
explained.
Regarding the arrangement of individual genes on strands of circular mDNA, there is considerable variability. In organisms studied thus far, the gene arrangements of four mammals (human, cow, rat, and fin whale) are identical to that of a mouse (see Table 2), a fish (Cyprinus carpio, a carp), and an amphibian (Xenopus laevus, a toad). When we compare a chicken (Gallus domesticus) to a mouse, we find a rearrangement in gene sequence with the displacement of the ND6 and cyt b genes and two tRNA genes. The sequential arrangement of genes in five other mDNAs are illustrated in Fig. 1 of Wolstenholme.4 In contrast to the similarities noted above, the genes of two insects (a honey bee, Apis mellifera, and a fruit fly, Drosophila yakuba) show many gene rearrangements, particularly of tRNA genes. When the gene arrangements of these two insects, a soil nematode, a sea urchin, and a sea anemone are compared to each other or to that of a mouse, scientists find many gene arrangement variations.
Since in any given organism, mDNA is separated into two strands (H and L) during processes of replication and transcription, and since these two strands may each be cut further, several opportunities for rearrangements in the order of genes on a particular strand occur. Among variations in known gene arrangements are those where a particular gene is sometimes found on the H strand of mDNA in one organism and on the L strand in a different organism. Since these two strands proceed in opposite directions, this type of gene arrangement is more difficult to explain than the rearrangement of genes on a single strand. These rearrangements might first appear to be explained by purely chance events. However, recognition signals, which allow strands to recombine in their original sequence arrangement in a particular organism, have not been fully studied. Clearly, cleavage and joining sites must be precise. For a rearrangement, they must be at the beginning or end of genes and not cause alterations (i.e., frame-shifts) in triplet codes of genes. As nucleotide sequences in mDNA of more organisms are studied, scientists will discover additional evidence of gene rearrangements in mDNA.
Genetic Code
Although a major argument for ancestral descent has been the universality of the genetic code, in recent years we have learned that the genetic code is not truly universal. This is especially evident when one examines mDNA. The usual genetic code, given in most textbooks, is still valid for nuclear DNA and also for most prokaryotes (i.e., organisms without a cell nucleus). The modifications of the usual genetic code as found in mDNA are shown in Table 3. It will be noted that there have been modifications in five of the sixty-four codons. In a metazoan phylogenetic tree suggested by Wolstenholme, it is proposed that changes in the genetic code have occurred at least eight times.5
Although initially, a change in codon usage
might appear to be minor, closer examination will reveal extreme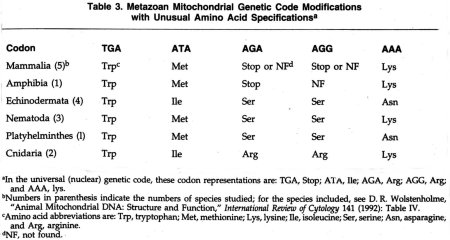 difficulties
imposed on a cell by a codon change. Two of the more dramatic codon changes in
mRNA are: (1) an AAA coding for asparagine in Echinodermata (e.g., a sea urchin
and Asterina pectinifera, a starfish) and Platyhelminthes (Fasciola
hepatica, a liver fluke) instead of an AAA coding for lysine as found in
other mDNAs and in nuclear DNAs; (2) a TGA codon indicating tryptophan in all
mDNAs, whereas TGA is a stop codon in nuclear DNAs. The first of these codon
changes involves a radical change in amino acids since the R-group of asparagine
has no charge and that of lysine has a positive charge.
difficulties
imposed on a cell by a codon change. Two of the more dramatic codon changes in
mRNA are: (1) an AAA coding for asparagine in Echinodermata (e.g., a sea urchin
and Asterina pectinifera, a starfish) and Platyhelminthes (Fasciola
hepatica, a liver fluke) instead of an AAA coding for lysine as found in
other mDNAs and in nuclear DNAs; (2) a TGA codon indicating tryptophan in all
mDNAs, whereas TGA is a stop codon in nuclear DNAs. The first of these codon
changes involves a radical change in amino acids since the R-group of asparagine
has no charge and that of lysine has a positive charge.
Let us consider in more detail what would be involved in the change of a lysine AAA codon to an asparagine AAA codon. In five different organisms other than echinoderms and platyhelminthes, there are about 80 AAA codons and about 8 AAG codons in mDNA designating lysine.6 Since replacement of 90% of the lysine codons in protein molecules by asparagine would surely be lethal to the organism, most lysine AAA codons in mDNA would have to change to AAG (or to a codon for another amino acid), since AAG would now be the only codon specifying lysine. Since lysine is such a critical amino acid in most proteins, this codon change from AAA to AAG for most lysine codons must occur in order to produce a functional protein.
Osawa, et al. have proposed a mechanism for this codon change.7 This proposal requires changes at the level of mDNA (Steps 1 and 4), tRNA (Steps 2 and 3), and proteins (Step 5). Changes at the levels of tRNA and proteins would presumably require changes in DNA, since structural changes in tRNA and proteins are ultimately directed by the information in DNA. Here are the proposed steps.
Step 1. A change of most mDNA codons for lysine from AAA to AAG. This would require 70ñ80 precise A->G point mutations.
Step 2. A change in the anticodon of tRNAlys from UUU to CUU, with a loss of tRNAlys (CUU) ability to serve in translation of AAA codons of messenger RNA.
Step 3. A change in tRNAasn so that it will translate AAA codons of messenger RNA as asparagine.
Step 4. A change of some asparagine mDNA codons (AAT or AAC) to AAA codons, or of some other selected codons to asparagine codons.
Step 5. Some corresponding changes in protein molecules (e.g., tRNA-aminoacyl synthetases and ribosomal proteins) which interact with aminoacyl tRNAs during the process of translation.
For this proposed mechanism to have significance, each of the first three steps must be completed before the next can begin. In other words, use of the mDNA AAA codon for lysine would have to be totally nonfunctional, before use of an AAA as an asparagine codon could begin. Otherwise, incorrect amino acids would be inserted into protein molecules.
The proposed changes in tRNA (Steps 2 and 3) would involve changes in the anticodon of tRNA, and would likely require changes in other regions of tRNA which selectively bind to ribosomal proteins or enzymes. Since information for these tRNA sequences resides in mDNA, appropriate nucleotide changes (point mutations?) in mDNA would be required to produce tRNA changes. Changes in proteins (Step 5) would require changes in nuclear DNA since genetic information for synthesis of these proteins resides in the nucleus. All changes in Steps 1 through 5 would have to be precisely coordinated in order to produce the one genetic code change of an AAA lysine codon to an AAA asparagine codon.
The change of a TGA codon from a stop codon (as found in prokaryotes and in nuclear DNA) to a mitochondrial tryptophan codon would be nearly as complicated. This codon change in the genetic code is found in all mDNAs with the TGA codon being used for tryptophan about 90% of the time rather than a TGG tryptophan codon. In mDNAs of six quite divergent species, there are about 96 TGA codons for tryptophan and only ten TGG codons (mean values).8 Even more importantly, in the process of translation, the messenger RNA-ribosome-tRNA complex could no longer recognize the UGA codon in messenger RNA as a stop signal. This surely would also require some structural changes in many different protein molecules involved in mitochondrial protein synthesis. Similar difficulties would be encountered in proposed scenarios for each of the other changes in the genetic code indicated in Table 3.
Implications of mRNA Studies for Theistic Evolution
Explanations for the similarities and differences in mDNA previously cited are varied. The predominant view of most evolutionary biologists today is that only a fully naturalistic explanation can be considered in which all changes are a consequence of purely chance events. In contrast, there are three possible levels of explanation that might be incorporated into an overall design theory of theistic evolution. As Howard Van Till has suggested (Level A): "...every one of these processes and every connective pathway in the possibility space of viable creatures is a mindfully designed provision from a Creator possessing unfathomable intelligence."9 Therefore, one can consider these events to be guided somehow (providence or governance?) by an intelligent cause, so that changes which would be nearly impossible by chance alone would become reasonable. Or one can consider the deistic evolutionary explanation of M. J. Corey (Level B): "...organisms possess the intrinsic capacity to organize themselves along developmental lines that have largely been pre-determined by information that is either contained within, or is assessed by, the genome."10 Or one can consider a third level which I have proposed (Level C): "...in the history of the origin and development of living organisms, at various levels of organization, there has been a continuing provision of new genetic information by an intelligent cause."11 My proposal must be involved in Corey's explanation to account for information in the genome providing the indicated intrinsic capacity. These theistic explanations would not deny the considerable role of chance events, but simply would insist that one also consider the possible role of a Designer.
Let us examine these different types of changes in mDNA (i.e., size differences, gene arrangements, and genetic code) to see how the above explanations may be applied to the data. The similarities and differences in the size of the mitochondrial protein genes could be given a naturalistic explanation, i.e., they are predominantly a consequence of point mutations, deletions, insertions, etc. However, it is difficult to see where natural selection could play any role as a driving force in these changes, since as far as we know, all of these genes and the proteins they express are fully functional. It seems more likely that a theistic explanation involving governance by the Creator (Level A) would play a role in guiding these size changes. This type of theistic explanation would not appear to be subject to any experimental test. Probability considerations would likely indicate that a theistic explanation would be a more satisfactory explanation than natural selection.
For gene rearrangements, a specific enzyme or ribozyme would be required for DNA cleavage sites and precise recognition of joining ends. The control of the processes of cleavage and of the joining of mDNA genes could very well involve genetic information for involved enzymes or ribozymes. Therefore, theistic levels B and C would have a role in these changes.
For changes in the genetic code, pure chance explanations appear totally inadequate. To suggest that fifty to eighty point mutations of AAA lysine codons would occur fully by chance to form the same number of AAG lysine codons as the required first step in a mDNA codon change is surely impossible based on probability considerations. Also, at present, there is no evidence in organisms of any intermediates for this proposed first step. On the other hand, this type of change could occur if the A->G base changes (point mutations?) were guided by an intelligent designer. With this explanation, changes could occur either rapidly over a short period of time, or more slowly over a longer period without necessarily being lethal to the organism. Since these changes in genetic code are so improbable by chance alone, it may very well be that some innate capacity in the genome (Level B) and some new genetic information (Level C) might be required for these genetic code changes.
For each of the other proposed steps in a codon change (Steps 2 through 5), scientists can provide an explanation based on a series of point mutations in either mDNA or nuclear DNA. However, the coordination of all required steps can only be explained as being under the guidance and control of a supreme intelligence. It seems likely that all three levels of a theistic explanation can be appropriately applied to these changes. Although I have examined, in some detail, the change of a lysine AAA codon to an asparagine AAA codon as an illustration of a change in genetic code, similar problems appear and similar explanations would apply for each of the other codon changes listed in Table 3.
As I noted in an earlier paper, the totally mechanistic theory of evolution assumes a monophyletic origin of life (i.e., all life began with an original archetypal cell).12 I also noted that a monophyletic origin is a possible component of my design theory of theistic evolution, but it is clearly not mandatory. A polyphyletic origin for living organisms by a common Creator is certainly also a possibility. By now suggesting three possible levels of explanation (Levels A, B, and C) by which a Creator might introduce changes into organisms, I do not wish to infer that there must have been a monophyletic origin of all organisms. Certainly a Designer could supply blocks of new genetic information for separate lineages. Since the design theory of theistic evolution calls for the continuing incorporation of new genetic information, the distinction between monophyletic and polyphyletic origins is not nearly as sharp as it is for a purely mechanistic theory of evolution.
Conclusion
In this paper, I have carefully examined some similarities and differences in a group of fairly similar animal mDNAs and have suggested explanations involving both chance and an intelligent cause. I have not examined other aspects of mDNA, such as nucleotide sequences of both protein and RNA genes, nor have I treated the question of more complex mDNAs in plants or in simple eukaryotic organisms (protozoa, fungi, etc.). Explanations involving chance and an intelligent cause appear appropriate for these unique mDNA features as well.
©1998
Notes and References
1M. A. Corey, Back to Darwin: The Scientific Case for Deistic Evolution (Lanham, MD: University Press of America, 1994), 2.
2D. J. Cummings, "Mitochondrial Genomes of the Ciliate," International Review of Cytology 141 (1992): 1ñ64. The entire volume of this journal is given to papers on mitochondrial DNA. Kinetoplastid mDNA is considered on pp. 65ñ8 (K. Stuart and J.E. Feigin) and fungi mDNA on pp. 89ñ127 (G.D. Clark-Walker) .
3D.R. Wolstenholme, "Animal Mitochondrial DNA: Structure and Function," International Review of Cytology 141 (1992): 173ñ216, Table II. Much factual information on mitochondrial DNA used in this paper is taken from this paper.
4Ibid.
5Ibid., Figure 2.
6Y. Chang, F. Huang, and T. Lo, "The Complete Nucleotide Sequence and Gene Organization of Carp (Cyprinus carpio) Mitochondrial Genome," Journal of Molecular Evolution 38 (1994): 138ñ155; and D.O. Clary and D.R. Wolstenholme, "The Mitochondrial DNA Molecule of Drosophila yakuba: Nucleotide Sequence, Gene Organization and Genetic Code," Journal of Molecular Evolution 22 (1985): 252ñ71.
7S. Osawa, T. Ohama, T.H. Jukes, and K. Watanabe, "Evolution of the Mitochondrial Genetic Code. I. Origin of AGR Serine and Stop Codons in Metazoan Mitochondria," Journal of Molecular Evolution 29 (1989): 202ñ7.
8Y. Chang, et al., ibid.; and R.H. Crozier and Y.C. Crozier, "The Mitochondrial Genome of the Honeybee Apis mellifera: Complete Sequence and Genome Organization," Genetics 133 (1993): 97ñ117.
9H.J. Van Till, and P.E. Johnson, "God and Evolution: An Exchange," First Things (June/July, 1993): 32ñ41, p. 38.
10Corey, ibid., 309.
11G.C. Mills, "A Theory of Theistic Evolution as an Alternative to the Naturalistic Theory," Perspectives on Science and Christian Faith 47 (1995): 112ñ22; also see _____________, "Theistic Evolution: A Design Theory Utilizing Genetic Information," Christian Scholar's Review XXIV (1995): 444ñ58.
12Ibid.
*ASA Fellow