 Science
in Christian Perspective
Science
in Christian PerspectiveScience
in Christian Perspective
Implications of Molecular Biology for
Creation and Evolution
ROBERT L. HERRMANN
Boston University School of Medicine
Boston, Massachusetts 02118
From: JASA 27 (December 1975): 156-159.
Survey of Molecular Biology
In 1953 Watson and Crick1 proposed the doublehelical structure of
DNA, the polynucleotide
molecule carrying the cell's genetic informaton. Four types of
heterocyclic nitrogenous
substances (bases) were bound into its structure by means of the
sugar 2-deoxyribose,
and phosphoric acid. The combination of a given base, a sugar and
phosphoric acid
is called a nucleotide (See Figure 1).
The crucial feature of the
proposed model
(Figure 2) was that the two chains of nucleotide building blocks were
complementary.
Every time an adenine nucleotide (A) is present in one chain, the
opposite chain
bears a thymine nucleotide (T). Likewise, every time a guanine nucleotide (C)
appears in one chain, the other chain bears a cytosine nucleotide
(C). The unique
pairing is the basis of precise duplication of the genes which is so necessary
for the hereditary mechanism. Gene duplication occurs by separation
of these two
chains and the synthesis of a new matching strand for each, so that there are
then two double-stranded structures where before there had been only one. Each
"daughter" molecule now carries the exact arrangement of nucleotide
units as the "parent" molecule, because the unique pairing
of the nucleotide
units prescribes that this be so. This is of utmost importance
because the linear
sequences of nucleotide units are eventually translated into linear sequences
of amino acid units for all of the protein molecules which make up the living
cell.
By 1960, experiments in many laboratories indicated that the cell's
protein molecules
were synthesized by a process involving transcription of the DNA sequence into
a second polynucleotide, messenger RNA, which, in conjunction with
various elements
of cell sap including complex structures called ribosomes, could
cause incorporation
of radio-active amino acids into protein-like polypeptide material (See Figure
3).
The great breakthrough in understanding this process came about when Nirenberg
and Matthaei found that synthetic RNA molecules could catalyze the
protein synthetic
process in these simple cell-free systems derived from bacteria.2 The synthetic
polynucleotides, produced with an enzyme
called polynucleotide phosphorylase, could be made with various combinations of
the component building blocks of natural RNA and then the protein synthesized
subsequently from these compounds in the cell-free system could be analyzed. In
this way it was discovered that the code signal for the insertion of
a given amino
acid into a protein structure was a sequence of three nucleotide units of the
polynucleotide. For example, three uridine nucleotides (a trinucleotide) in a
sequence of the RNA specifies the positioning of one molecule of the amino acid
phenylalanine in the sequence of the protein.
Later a more precise method of determining the coding sequence (the
"codon")
corresponding to a given amino acid was discovered, based upon the

Figure 1. The combination of a heterocyclic nitrogenous base with the
sugar 2-deoxyrihose
and phosphoric acid forms one of the nucleotide building blocks of
deoxyribonucleic
acid (DNA)
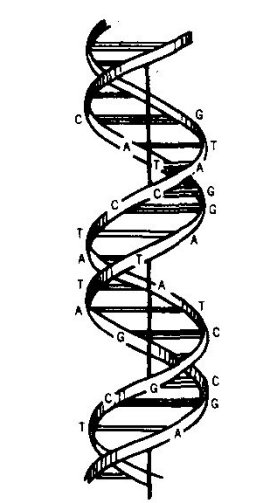
Figure 2. A representation of the double-helical model of DNA, illustrating the complementary base-pairing of adenine (A) with thymine (T) and quanine (C) with cytosine (C).
known involvement of a second type of RNA, transfer RNA (t-RNA) in
protein synthesis
(See Figure 3). This molecule was shown to occur in many formsat least one for
each amino acid found in proteinsand to function by adapting its amino acid to
the codon through a complementary sequence of nucleotides in its own structure.
It was found that even in the absence of protein synthesis, the specific t-RNA
molecules bind to complexes of ribosomes and messenger RNA.
Furthermore the messenger
RNA could be replaced not only by the synthetic polynucleotsdes used
in the earlier
experiments, but also by simple trinucleotides of precise structure.
In this method
a given trinucleotide representing a single codon could be examined
for its ability
to cause binding of various t-RNA molecules with their attached amino acids to
the ribosome structure. Those t-RNA molecules which bound must have have been
able to recognize that codon as the position for insertion of their particular
amino acid. In this way it was possible to assign each codon to a
specific amino
acid.
The Genetic Code
Figure 4 represents the genetic code as worked out for the bacterium E. coli.
Several interesting features are apparent with respect to evolution. The first
is the phenomenon called degeneracy. Note that for most of the amino
acids there
is more than one codon, e.g., phenylalanine is coded for by both UUU and UUC.
The third position can vary and specificity still be retained. Because of this
variation, it has been suggested that the original code was a doublet instead
of a triplet code. Variation in the 3rd position would also allow for the cell
to undergo mutational change without that change being necessarily lethal. CT
stands for codons which cause termination of a peptide chain (chain
termination)
and CI stands for chain initiation. Here the amino acid methionine
serves as the
initiating amino acid and in this case the methionine is first
formylated before
initiating peptide synthesis. There are also some interesting
relationships between
amino acids and their codons. Similar amino acids (similar side
chains) have similarities
in their code words, e.g., all non-polar amino acids (phenylalanine, leucine,
isolcucine, valine) have U as the second code letter. Also, aspartie acid and
glutamic acid, closely related structurally, both have GA as their
first two letters.
This suggests another evolutionary possibility; the specific code words for the
various amino acids
The implications of a universal genetic code are interesting, fascinating or threatening, depending on your viewpoint.
arose because of some physicochemical relationship between the
codon's nucleotides
and the amino acid which it specifies. This possibility has been
explored by several workers.3,4
A Universal Code
Extension of these experiments to other bacteria, to intermediate forms and to
mammals has led to the general conclusion that the genetic code is
universalthat
the same code words are used in both lower and higher organisms. For example,
with rabbit reticulocytes, 22 codons have thus far been shown to be translated
into amino acids identical to those in the F. co/i bacterial system. The data,
though incomplete, point to a universal code.5
Likewise, the protein-synthetic mechanisms in prokaryotic and
eukaryotic systems
appear to be quite similar. For example, the chain initiating codon
which in the
bacterium E. coli involves a special form of transfer RNA, which
places the amino
acid methionine in the chain at that point, is also utilized by yeast, by wheat
germ, by mouse liver and rabbit reticulocytes. Other features of the mechanism
also appear similar.
The implications of such a mechanism are interesting, fascinating, or
threatening,
depending on your viewpoint. The existence of a universal code would imply that
there was indeed a single precursor of all living things, a primitive
system capable
of replication and information transfer from which all the present living forms
developed.
A Specific Model
In fact, mechanisms have been proposed for the origin of such a
system given the
necessary building blocks which appear to have been present on the
primitive earth. Quastler, in his Emergence of Biological Organization6 suggests one
such mechanism.
As we have indicated, the genetic material, DNA, is made up of two
polynucleotide
chains whose most unique feature is the complementary pairing of the nucleotide
building blocks, A to T and G to C.
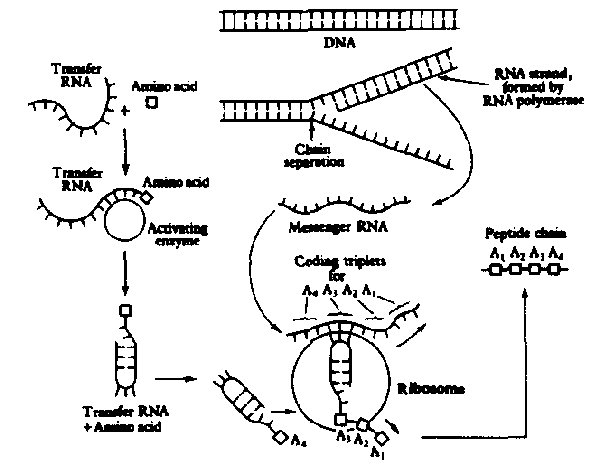
Figure 3. The scheme for protein synthesis. DNA is "read out" in the
form of messenger RNA, which travels to the cyptnplasm and binds to structures
called ribosomes. Here, a series of transfer RNA molecules, at least one type
for each protein amino acid, carry their appropriate amino acid to the ribosome
and align with a specific coding sequence on the messenger to form the proper
sequence of the protein chain.
Even the informational content of a living system may have arisen from the apparently random way in which the nucleotide building blocks of the first successful system were incorporated into a polynucleotide polymer.
In Quastler's proposal for the origin of the nucleic acid system
(Figure 5), nucleotide
building blocks react with each other to form single polynucleotide
chains. This
process would he very slow in the absence of enzymes, but Quastler
estimates that
there would still be 400 periods during geological time available for
this reaction.
The single chains thus formed may then react further with additional nucleotide
units, by the nucleotide pairing principle, to form intermediate
structures which
are partly single-chained and partly double-chained. This reaction is much more
favorable than is the original reaction to form the single
polynucleotide chain.
Completion of this reaction leads to fully double-chained structures which may
then reversibly separate to form single chains.
The unique feature of such a system is that it gives rise to a kind
of "information,"
in the sense that the first polynucleotide chain to be formed has a far greater
chance for survival than any later arrivals. Thus it is able to
compete more favorably
for nucleotide units, since the reaction of the polynucleotide chain
with nucleotides
is favored over the original synthesis of the polynucleotide. The first chain
thus becomes the progenitor of a unique polynucleotide system made up of itself
and its "sister" chain, in which each nucleotide unit is the opposite
pairing partner for the other chain-i.e., A opposite T and G opposite
C. The information
content of the system, as Quastler sees it, is of the nature of an
"accidental
thought remembered." The original arrangement of nucleotide units in the
polynucleotide chain might have been arrived at by purely random interaction,
but once the chain is formed, that particular arrangement and that of
its sister
strand are the only allowable structures. A good analogy would be the numbers
of a combination lock. Prior to their choice for the combination, the numbers
are of no consequence. But after being introduced as the numbers of
the combination
they are now information.
The importance of Quastler's argument lies in its demonstration of the way in
which the evolutionary
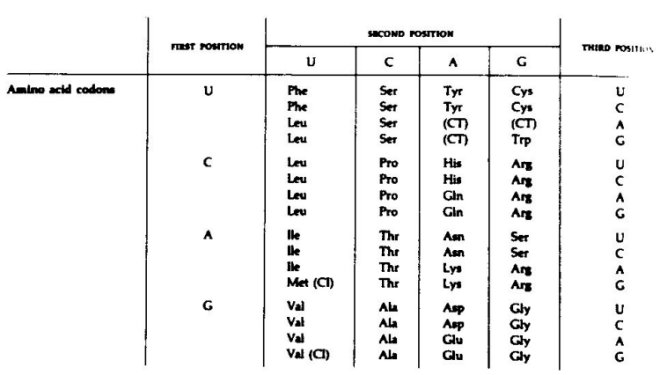
Figure 4. The genetic code as worked out for the bacterium E. coli.
ORIGIN OF A PRIMITIVE NUCLEIC ACID SYSTEM
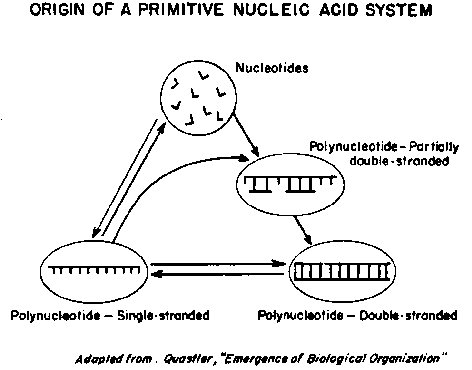
Figure 5. Quastler's model for the origin of a nucleic acid system. Nucleotides
react to form single-stranded polynucleotides. The latter can undergo
a more favorable
reaction to form partially double-stranded structures which
eventually give rise
to a double helical polynocleotide with a complementary base-paired
structure.
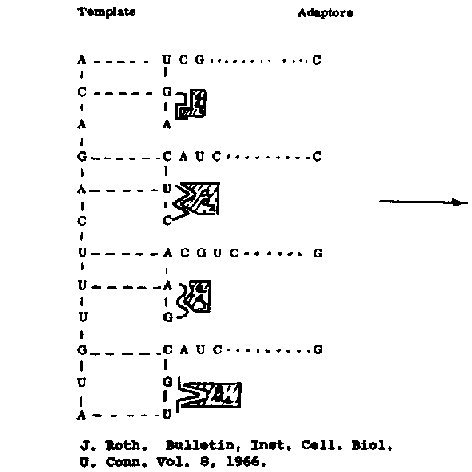
Figure 6. A proposal for the attachment of primitive counterparts of amino acid
transfer RNA molecules to the template of a polynucleotide system,
with the eventuality
of the synthesis of amino acid polymers.
principles of selection and competition can be applied at the chemical level.
For here, from apparently random events, a system may be seen to arise that is
capable of reproducing and propagating itself and hence acting as a
kind of primitive
genetic information.
Explanation of Protein Synthesis
The extrapolation of this scheme to
an explanation
for present mechanisms of protein synthesis may be made on the same principles
of chemical evolution (Figure 6). Polynucleotides could react with amino acids
with some degree of specificity3-4 to give adapter molecules similar
to the amino acyl, t-RNA's of present protein synthesis. Complementary base pairing of these
molecules to the original polynucleotide system would provide the opportunity
for the system to couple amino acids in a variety of different
arrangements, depending
upon the sequence of the original polynucleotide, and,
bacterium if one or more amino acid sequences proved to have
enzymatic activity,
there would be the tremendous
advantage, by virtue of the self-duplicating property of polynucleotides, for
this system to "remember" it.
Thus even the informational content of a living system may have arisen, in its
simplest form, from the apparently random way in which the nucleotide building
blocks of the first successful system were incorporated into a polynucleotide
polymer. Considering the available data on the universality of the code and a
theoretical framework for its origin, the description of life's
origins in a purely
mechanistic sense would appear to lie within the grasp of modern
molecular biology.
Other Explanations
However, this should not lead to any feeling on the part of the scientist that
his explanation of origins excludes other explanations-e.g., a theological one.
Jacques Monod may object in his Chance and Necessity 8to the idea of a
"necessity
rooted in the very beginning of things," but there is certainly no valid
reason to exclude such a possibility. The Scriptural view of origins
in fact places
its primary emphasis on this very idea of purpose and meaning in the creation;
life was made with precision and order, with quite precise ends in view.
Part of the concern of many Christians about evolutionary theory is that they
fear that a mechanistic explanation negates God. But this problem has
been dealt
with in an excellent fashion by Donald MacKay in his booklet Science
and Christian
Faith Today.9 God's activity includes not only his originating
activity (Genesis)
but also his sustaining activity. The Apostle Paul writes in
Colossians 1, speaking
of Jesus Christ, "in Him all things hold together" (Col.
1:17) and the
writer to the Hebrews speaks of Christ "upholding all things by His Word
and power." (Heb. 1:3) MacKay points out that the phrase "upholding
all things" might better be translated "holds in being all
things"
emphasizing God's immanent activity, without which the universe would not just
stop but rather without which it would cease to exist.
The picture of God as a kind of machine tender seems completely inadequate in
light of this verse. Rather, God's activity is more like that of a
master artist,
who paints-in a dynamic fashion-a constantly changing picture. Something like
this is suggested by the picture that a television receiver presents. The
analogy is especially useful because it emphasizes the dynamic aspect of God's
activity-"holding in being" the universe. For by simply ceasing his
activity, it would be obliterated much as the television picture may he totally
altered by simply flipping a switch. By bringing the focus to God's
immanent activity,
we see also the inapplicability of such arguments as "evolution leaves no
room for the God of action, precluding his function except in areas
of fast-disappearing
links." The true picture is that God acts in all of Reality, not
just where
we cannot apply a scientific explanation. It is all His! As MacKay
says "the
whole multi-patterned drama of the universe is His." Also, the emphasis of
Scripture is that God has ordered his Creation not by virtue of
producing a perfect
mechanism but rather because of His complete faithfulness. It is the ultimate
basis for things, the raison d'etre, with which the Bible is dealing
in its consideration
of origins, and the character of the Creator is therefore its primary
concern.
Science gives us the view of how life may have come about. Its view
is descriptive,
and does not in any ultimate sense account for what it describes. The most we
can say based on present data is that God may have used an
evolutionary mechanism
to achieve the purposes delineated in Scripture.
BIBLIOGRAPHY
1J. Watson & F. Crick, "The Structure of DNA." Nature
171 736 (1953).
2M. Nirenherg and J. Mattaei, "The Dependence of Cell-free
Protein Synthesis
in E. coli upon Naturally Occurring or Synthetic Polyribonucleotides. Prnc. Nat.
Acad.Sci., U.S. 47 1588 (1961).
3Woese, C. R., "The emergence of genetic organization",
in Exobiology, C. Ponnaniperuma, editor., Frontiers in Biology, Vol. 23, North.
Holland, 1972 pp. 318-327.
4Pclc, S. R. and Welton, M. C. E. "Steriochemical relationship
between coding
triplets and amino acids." Nature
209 868-870 (1966).
5J. Lucas-Lenard and F. Lipmann, "Protein Biosynthesis" Annual Review
of Biochemistry 40 409 (1971).
6H. Quastler, "Emergence of Biological Organization" Yale U.
Press, New
Haven, 1964 pp. 7-16.
7D. Reanney and R. Ralph "A Speculation on the Origin
of the Genetic Code", J. Theor. Biol. 15 41 (1967).
8J. Monod, Chance and Necessity, Vintage Books, New York. 1972, pp. 143-6.
9D. MacKay, Science and Christian Faith Today, Church Pastoral-Aid Society
(London) 1960.